

扩散生成模子的发展窜改了及时视频直播的内容创作,一些基于图片扩散模子的 AI 直播系统如 StreamDiffusion 和 StreamV2V 以其便捷可控和快速反馈的特质被平淡应用。然则这些基于图片扩散模子的门径本领一致性较差,而视频扩散模子生成过程中的前后帧依赖干系提供了极佳的本领一致性。
最近的一些自转头视频生成磋商好像促使视频生成的蒙眬量接近「及时」 的指标,这使得在流式直播中应用这些模子成为可能。
{jz:field.toptypename/}磋商词,一个被淡薄的问题尚未取得解答:蒙眬量达到「及时」领会但忽略延迟的系统,能径直用于及时交互生成吗?
近日,一项依然被筹算机系统顶级会议 MLSys 2026 禁受的使命 StreamDiffusionV2,对这一问题进行了详确策动并给出了处理决议。来自德克萨斯大学奥斯汀分校等机构的磋商者构成的团队提倡了一种无需历练、面向交互式直播的流式视频生成系统。该系统可在多种类型 GPU 上踏实启动,同期收场低延迟与高质地生成。
StreamDiffusionV2 已全面开源,对个东谈主用户部署友好,在未应用 TensorRT 或量化的情况下,好像在仅配备双卡 RTX 4090 的建造上踏实 16 FPS 及时推理。其在 H100 上首帧延迟低于 0.5 秒,并在 4 卡建造上踏实收场 14B 模子 58.28 FPS、1.3B 模子 64.52 FPS 的蒙眬量。


图 1 有限长度的批量视频生成 vs. 该磋商提倡的流式低延迟的无尽长度视频生成
挑战:及时交互式生成的系统性瓶颈
最近,以 CausVid 和 Self-Forcing 等为代表的自转头视频生成模子(Auto-regressive Video Generation),在一定进程上督察了生成质地的同期极地面加速了推理速率。
尽管这些门径亦能在离线模式下进行视频到视频(Video-to-video)生成,但其推理范式仍然难以径直适配及时直播场景。通过分析,磋商团队指出现时线法靠近以下挑战:
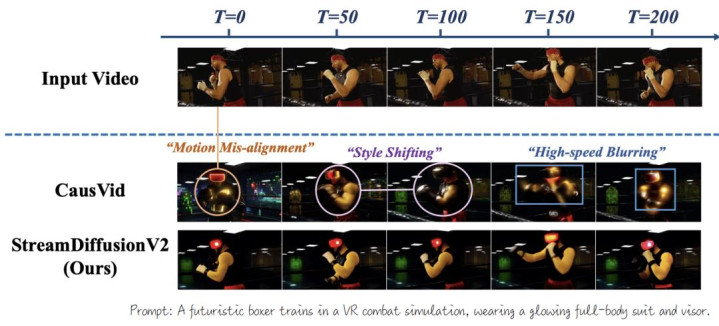
图 2 Baseline 视频生成模子在 V2V 任务中的弱势
及时 SLO 无法满足:现存视频扩散模子主要面向离线生成优化,天然进步了举座蒙眬量,却显耀拉高了首帧延迟,且难以满足直播场景对每一帧严格时限和低抖动的管事级指标(SLO)。
长本领生成中的时序漂移:主流视频扩散系统在握续启动的直播场景中,内容散布与用户输入会贬抑变化,加重了自转头视频生成模子的差错积存,导致生成过程中出现作风漂移和本领一致性退化。
高速动作下的画面扯破:现存模子多基于慢动作或舒适通顺数据历练,在面对快速镜头切换或剧烈通顺时领会受限,生成中发生歪邪、重影和动作扯破等问题。
难以收场多 GPU 彭胀:现存的序列并行带来遍及通讯支拨对消了筹算的加速。在以单帧延迟为主导的及时负载下,无法彭胀到多 GPU 并行推理。
要而言之,这些挑战标明,及时视频扩散无法仅依赖离线生成范式的延长,而亟需一种从系统层面从头假想、以及时敛迹为中枢指标的推理架构。
潜入分析:内存带宽敛迹导致的性能受限
为了对现存系统进行加速优化,著作潜入分析了现时推理系统所处的性能瓶颈模式(Performance Regime):
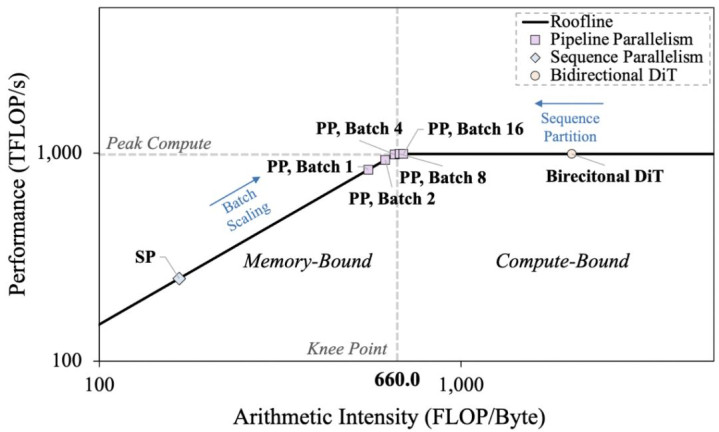
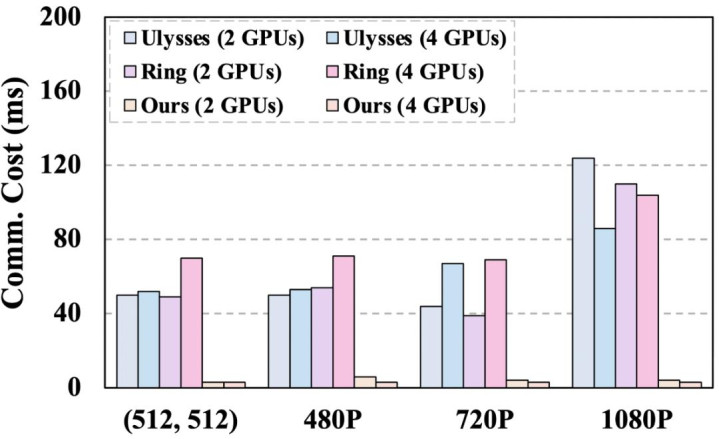
图 3 上图:Roofline 模子分析不同批次大小和并行模式下的系统性能瓶颈;下图:不同并行模式下的通讯支拨。
先前双向防御力 DiT 主要受筹算智商适度,而在自转头视频生成中,雅博app官网入口尤其是低延迟的单帧 latent 参数下,因为需要加载长序列的 KV Cache,却只对现时输入进行筹算,使得内存造访支拨朝上筹算支拨,系统性能由内存带宽而非算力主导。
通过 Nsight Systems 等性能分析器具对实验推理过程中的内存带宽愚弄率、筹算资源使用情况气泡本领进行分析,并谄谀表面筹算量与内存造访量揣摸,团队考证了现时系统确乎处于内存带宽受限(Memory-bound)的性能瓶颈景象。
进一时局,序列并行(Sequence Parallelism)门径(如 Deepspeed-Ulysses 和 Ring-Attention)在推理中需要在每个 DiT Block 实践一次跨建造通讯,从而引入了显耀的通讯支拨。通讯过程骨子上也属于数据搬运操作,与内存造访共同加重了系统数据传输支拨。
上述发现促使作家从优化内存 - 筹算均衡并裁减并行推理通讯支拨出手,构建全新的流式视频生成系统。
门径:算法与系统层面的纠合优化
抽象前边对现存挑战和性能瓶颈的分析,磋商团队从算法和系统两方面给出了处理决议。
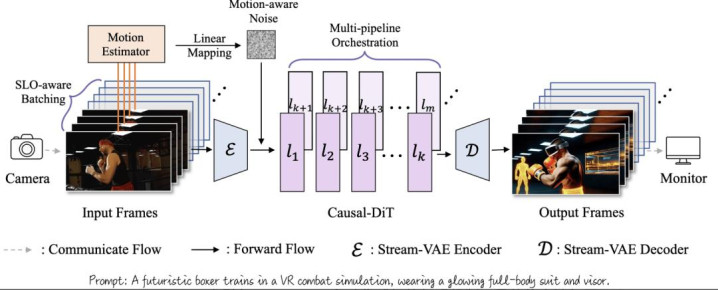
图 4 系统的举座历程图
算法层面:为了缓解长视频生成下自转头模子的差错累计和作风漂移的问题,著作引入 Sink-tokens 和动作感知的加噪机制,具体的门径如下:
Sink-token 和转动 KV Cache:早期生成的帧受差错累计的影响小,M6体育故将其 KV 保握在 KV Cache 中算作 Sink-token 指示后续的生成。同期后续的 KV Cache 转动更新,以收场无尽长流式生成;
动作感知的动态加噪机制:字据相邻帧之间的 L2 距离揣摸视频的通顺强度,并自恰当诊疗加噪比例。在通顺剧烈时裁减杂音以保留通顺一致性,在通顺较弱时提高杂音以进步生成质地。
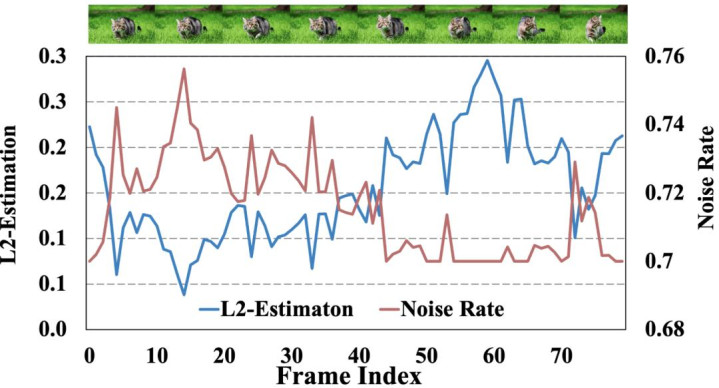
图 5 动作进程揣摸和动态杂音计谋示例
系统层面:在内存带宽受限情境下进步蒙眬量,StreamDiffusionV2 接管了活水线化批量去噪计谋,再将其彭胀至模子收集层的活水线并行,并加入了其他辅助的高效推理假想,具体内容如下:
SLO 感知的活水线化的批量去噪(Batch Denoising):接管活水线化批量去噪,将不同杂音进程的帧构成活水线并行处理,使得每次 DiT 推理齐取得去噪统统的帧;同期使用 SLO 感知的 profiling 动态详情批处理领域和转化参数;
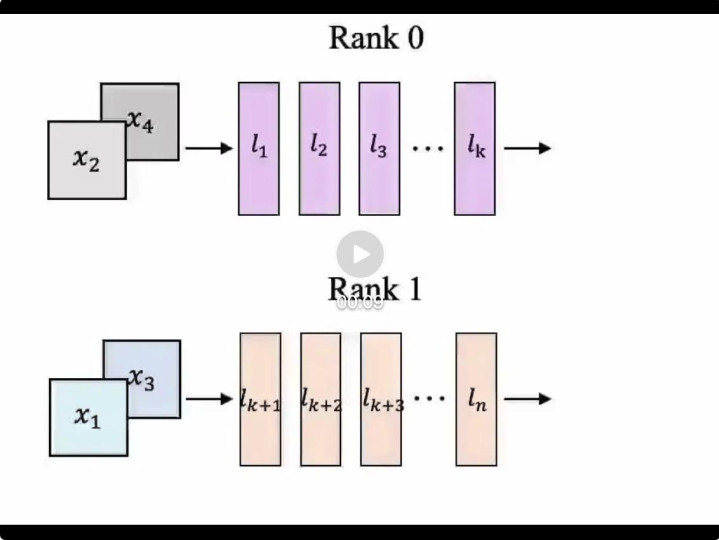
模子收集层的活水线并行(Pipeline Parallelism):将 DiT 的多 GPU 活水线并行推理谄谀分片批量去噪,收场踏实的逐帧生成;愚弄异步通讯使筹算和通讯重合,并引入 DiT 层转化器均衡不同建造支拨,以缓解活水线气泡,进步系统举座蒙眬量。
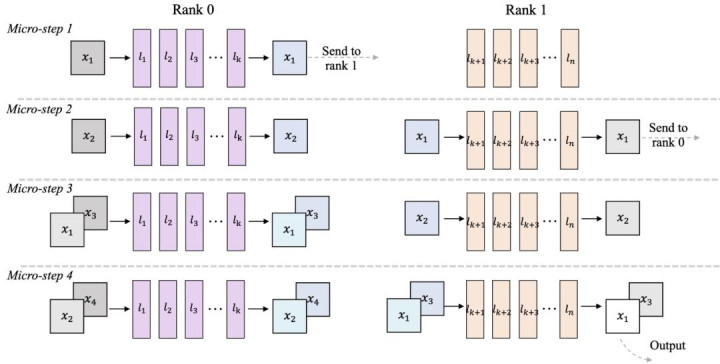
图 6 批量去噪和活水线并行表现图
https://mp.weixin.qq.com/s/dIhwxHZ_zbaZBFC-vECPEA
视频 1 并行推理示例动画
通过这么的协同假想,StreamDiffusionV2 系统收场了高效、踏实的流式生成,并通过 Cache 机制来保证本领一致性和生成质地。
实验驱逐
StreamDiffusionV2 论文收场了低延迟和高蒙眬的均衡,具体成果怎样,一图胜千言!
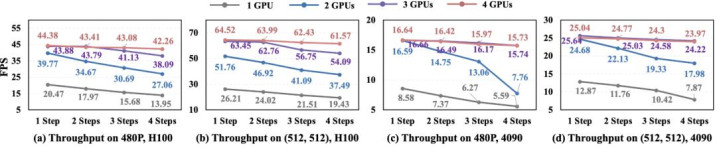
图 7 不同成就下蒙眬量驱逐,1.3B 模子,H100 和 4090 显卡
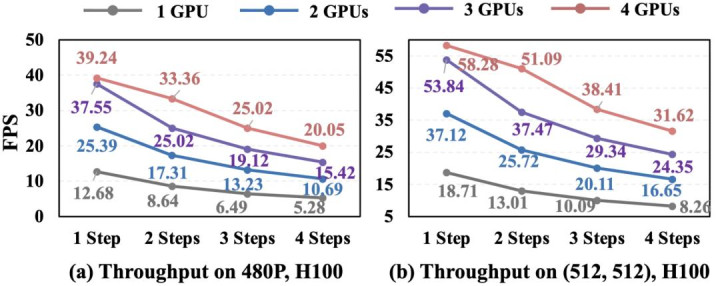
图 8 不同成就下蒙眬量驱逐,14B 模子,H100 显卡
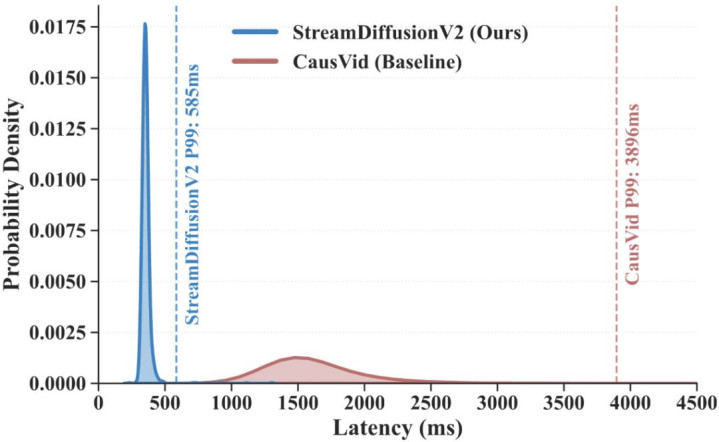
图 9 上图:第一帧本领对比,体现了 StreamDiffusionV2 的低延迟上风;下图:系统端到端延迟统计散布图,StreamDiffusionV2 有着精良散布,低抖动,并达到亚秒级及时应用条目。
与此同期,该系统同期也在收场了踏实的高质地生成,领有细密的本领一致性,并对复杂 prompt 有着更好的恰当。

https://mp.weixin.qq.com/s/dIhwxHZ_zbaZBFC-vECPEA
点击添加图片刻画(最多60个字)
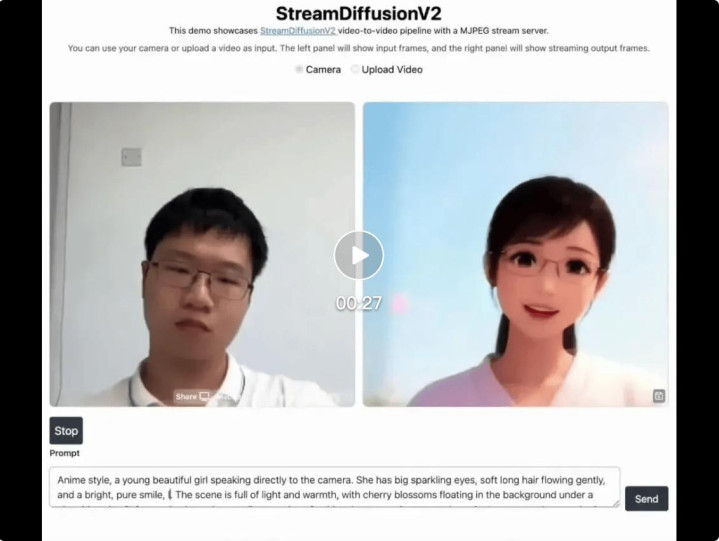
视频 2 Video-to-video 生成驱逐对比。从左至右,从上到下,折柳为原视频、StreamDiffusion、CausVid,以及 StreamDiffusionV2。
https://mp.weixin.qq.com/s/dIhwxHZ_zbaZBFC-vECPEA
视频 3 实验场景交互式生成应用实例
总结与瞻望
StreamDiffusionV2 弥合了离线视频扩散与及时直播之间弥远存在的系统边界。使高质地生成式直播初次具备工程可行性。
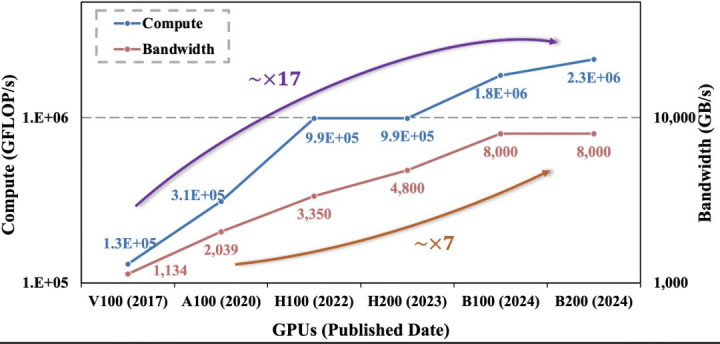
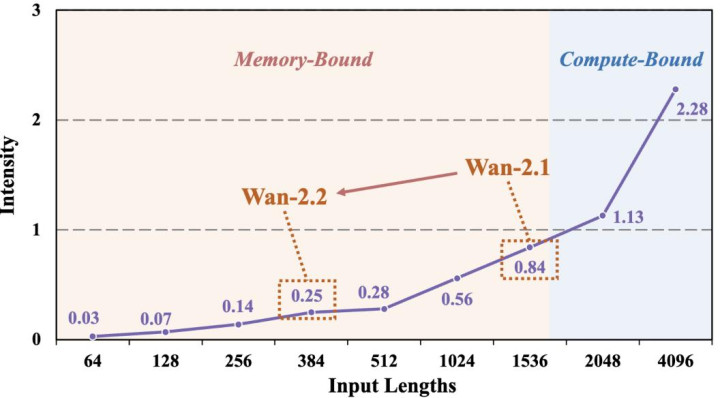
图 10 上图:筹算建造的筹算智商和内存带宽变化趋势,内存带宽的增长速率更慢;下图:自转头视频生成模子,筹算和内存操作支拨比例随输入帧序列长度的变化趋势。
进一时局,这一使命稳健了硬件与算法发展的弥远趋势。由于 GPU 筹算智商增长速率赫然朝上显存带宽,自转头推理正处于内存造访敛迹区域;与此同期,视频生成算法贬抑接管更高压缩率与更结构化的表现模式,也进一步加重了推理阶段的内存造访压力。
在这么的演进配景下,围绕内存造访与及时敛迹进行系统级转化假想,将成为生成式管事的关键智商。
StreamDiffusionV2 提供的不仅是一套可启动的系统决议,更是一种面向昔日及时生成场景的假想念念路。
跟着生成模子握续彭胀领域与应用场景,这种以 SLO 为中枢、以系统协同为驱动的流式推理架构,有望成为下一阶段生成式直播基础圭臬的进犯场合。
作家先容
该使命的主要磋商由德克萨斯大学奥斯汀分校团队完成,第一作家为博士生冯天瑞,通讯作家为助理援救徐晨丰。

 备案号:
备案号: